
One platform — standardized, built and operated by many.
One platform — standardized, built and operated by many.
This blog post shows how the SCS Harbor container registry instance was migrated from one cloud service provider to another using lift and shift cloud migration. As part of the migration, several improvements were also made, such as the Harbor version upgrade, the upgrade of Harbor registry components to a highly available (HA) setup, and OCI distribution registry storage migration from persistent volume (PV) to the Swift object storage. We will describe the challenges and issues we faced during this process.
Note that this blog post extends the official Harbor’s docs pages: “backup-restore” and “upgrade-and-migrate” with up-to-date commands, explanations, and detailed descriptions of prerequisites needed for these maintenance tasks.
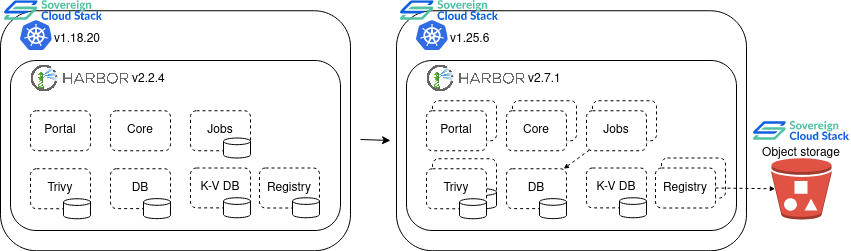
Initially, the SCS Harbor container registry instance (https://registry.scs.community/) was running on the SCS infrastructure in the Kubernetes v1.18.20 cluster. This Harbor instance with version 2.2.4 was deployed by harbor-helm chart v1.6.0. This version of harbor-helm chart is affected by security issue with high severity. It is possible for anyone to forge a JWT token and push/pull images to/from Harbor private registries without any authentication. Besides the outdated registry version and the outdated version of the underlying Kubernetes cluster, this was another good motivation for the migration and upgrade of the SCS Harbor container registry instance. In addition, the Harbor deployment didn’t use the ability of Harbor to operate in the high availability mode, which might be beneficial for many reasons.
Our plan was to migrate this Harbor instance to the up-to-date SCS Kubernetes cluster with version 1.25.6 which was spawned on SCS-compatible infrastructure, but operated by a different cloud service provider. After the migration process, the upgrade to the latest stable version of the Harbor container registry v2.7.1 using the latest stable version of the harbor-helm chart v1.11.1 (that is not affected by mentioned security issue) was planned. The upgrade procedure also included increasing the number of replicas for Harbor fundamental services to >=2 to achieve the HA of Harbor components. The HA mode for the Harbor database (Postgres) and Harbor key-value database (Redis) was not planned this at time. Most of Harbor’s components are stateless, hence you can simply increase the number of replicas to ensure that components are distributed across multiple worker nodes and are HA. In addition to the Harbor database and the k-v store, there are two Harbor components that are stateful and their state needs to be shared across their replicas: the job service and the registry. Harbor offers two ways to achieve the HA of these components. In the case of the job service, the administrator can configure shared persistent volumes for all pods (this requires persistent volume RWX support), or alternatively, the administrator can configure the Harbor database as a storage backend for job service instead of PVs. As the RWX access mode for PVs is not currently supported, the second option was planned. In the case of the registry service, the administrator can again configure shared PVs for all pods, or alternatively, an external object storage could be used as a the registry storage backend. Our first choice was to use object storage as a backend for image blobs as the amount of data here is expected to be large and the object storage drive is a good option if you want to store this type of unstructured data at scale. See the original and planned high-level architecture diagram below:
This SCS Harbor container registry migration scenario uses the Velero tool that allows you to move the Harbor instance as-is from one Kubernetes environment to another environment using the backup and restore procedures. Our clusters live in different SCS cloud service providers and for simplifying further references to them, let’s call them Cluster_A and Cluster_B. Cluster_A represents the outdated Kubernetes cluster and Cluster_B represents the target Kubernetes cluster to which we wanted to migrate our Harbor. See the migration high-level diagram below:
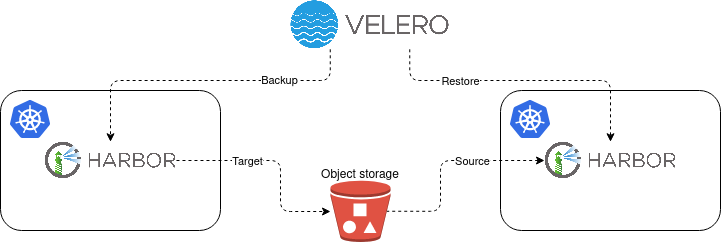
As Cluster_A and Cluster_B do not share the same infrastructure it is convenient to use a full Harbor data backup (not a snapshot) using Restic integration in Velero. Velero with Restic requires Kubernetes version 1.16 or higher in both clusters, which we met.
To migrate Harbor resources and data between cloud providers we used OpenStack Swift object storage with S3-compatible API as a storage backend for Velero. We created an S3 bucket on Swift object storage and EC2 credentials that will be later used by Velero.
The Swift object storage service does not support application credentials authentication to access S3 API. To authenticate in S3 API, you should generate and use the EC2 credentials mechanism. Note that EC2 credentials are associated with a user and are scoped only to a specific project. EC2 credentials are not protected by limited roles, expiration time, or access rules, therefore they have the same access as the user who created them. If you want to restrict EC2 credentials you could use application credentials for their creation, then EC2 credentials should inherit a (potentially) limited subset of roles that the creator owns (see this for details).
We generated EC2 credentials, using the regular user account as follows:
$ openstack ec2 credentials create
+------------+----------------------------------------------------------------------------------------------------------+
| Field | Value |
+------------+----------------------------------------------------------------------------------------------------------+
| access | <aws_access_key_id> |
| links | {'self': 'https://api.gx-scs.sovereignit.cloud:5000/v3/users/<user_id>/credentials/OS-EC2/<project_id>'} |
| project_id | <project_id> |
| secret | <aws_secret_access_key> |
| trust_id | None |
| user_id | <user_id> |
+------------+----------------------------------------------------------------------------------------------------------+
We stored the provided S3 API credentials in the file ~/.aws/credentials. This credential
file is then used as an access and secret source for AWS CLI tool and also as a source
for Velero. A new migration bucket has been created. Note that the following command
contains endpoint-url argument that points the AWS CLI to the SCS OpenStack Swift object storage API.
aws --endpoint-url https://api.gx-scs.sovereignit.cloud:8080 s3 mb s3://velero-backup
Velero is an open-source tool to safely backup, restore, perform disaster recovery, and migrate Kubernetes cluster resources. Its server runs inside the Kubernetes cluster, and can be controlled via the handy Velero CLI tool. If your environment is a Linux distribution you can use the following steps and install the Velero client from the GitHub release binaries:
wget https://github.com/vmware-tanzu/velero/releases/download/v1.10.2/velero-v1.10.2-linux-amd64.tar.gz
tar -zxvf velero-v1.10.2-linux-amd64.tar.gz
sudo mv velero-v1.10.2-linux-amd64/velero /usr/local/bin/
Then we installed Velero server component along with the appropriate plugins, into both
clusters (Cluster_A and Cluster_B). The following command creates a deployment called velero in
the namespace called velero. The namespace will be created by this command.
velero install \
--kubeconfig <path to the kubeconfig file of Cluster_[A,B]> \
--features=EnableAPIGroupVersions \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.6.1 \
--bucket velero-backup \
--secret-file ~/.aws/credentials \
--use-volume-snapshots=false \
--uploader-type=restic \
--use-node-agent \
--backup-location-config region=RegionOne,s3ForcePathStyle="true",s3Url=https://api.gx-scs.sovereignit.cloud:8080
Note that the installation command uses the bucket velero-backup that has been created
a few steps earlier as well as EC2 credentials located in ~/.aws/credentials file.
Also, note that the region and s3Url parameters are SCS specific.
The EnableAPIGroupVersions feature has been enabled as well. It is not unusual to see the
Kubernetes API group versions differ between clusters across several minor releases.
Our clusters differ in 7 minor releases (Cluster_A version is 1.18.20 and Cluster_B
version is 1.25.6) hence differences between API group versions are expected. Velero
with “EnableAPIGroupVersions”,
backups all Kubernetes API group versions that are supported on the source Cluster_A.
Then, if this feature is also enabled on Cluster_B, Velero will make the best choice
of Kubernetes API version which is defined in the group name of both source
Cluster_A and target Cluster_B based on API group version priority order.
Keep in mind that this experimental feature does not support cases when the API group
name does not exist in the target cluster. As a good example for this case could be an
ingress resource that API group name extensions is no longer served as of v1.22.
In that case, Velero tries to restore the resource in the target cluster, and if the
resource API group is not supported, the restore is skipped. So in some special cases,
some resources could not be restored which may lead to some unexpected issues.
Our plan was to upgrade the Harbor instance right after the migration work, so the
helm upgrade procedure should ensure that missing resources will be deployed with the
right API group versions.
It is a good practice to configure the backup location in the Cluster_B as read-only.
This will make sure that the backup created from Cluster_A is not deleted from the object
store by mistake during the restore to Cluster_B. To do this we modified the default
BackupStorageLocation resource in Cluster_B:
$ kubectl -n velero --kubeconfig <path of Cluster_B kubeconfig> edit backupstoragelocations default
# Set the `accessMode` to `ReadOnly`
# spec:
# accessMode: ReadOnly
The official Harbor docs page for backup and restore contains a list of limitations of Harbor backup/restore procedure using Velero. It is a good idea to go through this section to be aware of a potential impact on your Harbor instance. See selected items from the list with explanations:
$ kubectl --kubeconfig <path of Cluster_A kubeconfig> logs -l component=registry -c registry --tail -1 | grep -i purge
time="2023-04-17T09:02:08.320514706Z" level=info msg="Starting upload purge in 24h0m0s" go.version=go1.15.6 instance.id=xxx service=registry version=v2.7.1.m
time="2023-04-17T09:09:08.321004645Z" level=info msg="PurgeUploads starting: olderThan=2023-04-10 09:09:08.320738572 +0000 UTC m=-604379.969424455, actuallyDelete=true"
time="2023-04-17T09:09:08.331433127Z" level=info msg="Purge uploads finished. Num deleted=0, num errors=0"
...
After preparing and installing all prerequisites, we were ready to migrate SCS Harbor
from Cluster_A to Cluster_B. The first step was to set Harbor in Cluster_A to the
ReadOnly mode.
This protected our Harbor instance from deleting repositories, artifacts, tags, and pushing images.
This also ensured that the Harbor instance in Cluster_A will be in sync with the Harbor instance
in Cluster_B after we restored the Harbor instance from the backup in Cluster_B.
Then we excluded the volume of Harbor’s k-v database (Redis) from backup in Cluster_A:
kubectl -n default --kubeconfig <path of Cluster_A kubeconfig> annotate pod/harbor-harbor-redis-0 backup.velero.io/backup-volumes-excludes=data
The Velero backup command below successfully created a full backup of all resources in the given namespace including their persistent storages (besides Redis PV). It took several minutes as the registry used PV as a storage backend for image blobs.
velero backup create harbor-backup --kubeconfig <path of Cluster_A kubeconfig> --include-namespaces default --default-volumes-to-fs-backup --wait
The restore procedure is as simple as the backup one, just one Velero command did the whole magic:
velero restore create harbor-restore --from-backup harbor-backup --kubeconfig <path of Cluster_B kubeconfig> --wait
After we restored the Harbor instance we realized that the ingress resource was not
migrated because of an API group name change (extensions -> networking.k8s.io).
Besides this issue, we found all Harbor services up and running and after brief check
of services logs we declared the migration work as done.
This new instance of the SCS container registry running in Cluster_B was not publicly
accessible yet as the DNS record still pointed users to the Cluster_A IP address.
More importantly, this new instance was still running the outdated Harbor version and was still
affected by the security issue mentioned above.
The upgrade to the latest stable Harbor version should resolve all mentioned issues.
Let’s proceed.
Initial Harbor installation in Cluster_A used SCS k8s-harbor project as a source. This project has been updated before this migration and upgrade work. It contains several predefined environments that install Harbor in various setups. It uses FluxCD for managing harbor-helm chart and also enables installation of dependencies like the ingress-controller, cert-manager, etc. It also allows administrators to generate random secrets that should override default values in productive setups. The environment used for reference SCS container registry installation is called public.
Our plan was to upgrade Harbor from version 2.2.4 which was deployed by harbor-helm v1.6.0 to Harbor version v2.7.1 which should be deployed by harbor-helm v1.11.1.
Harbor recommends step-by-step upgrades when you want to upgrade Harbor across multiple minor versions. Normally, Harbor helm upgrade from 2 minor versions lower should be tested. The step-by-step upgrade is needed because of possible DDL changes in the Harbor database, which should be performed by the Harbor core service via migrations scripts.
Our planned upgrade path was faster, as we skipped several minor releases. This was tested multiple times on another Harbor instance, and in addition, we found a record that similar upgrade path works in related harbor-helm issue.
Upgrade path: harbor-helm v1.6.0 (Harbor v2.2.4) -> harbor-helm v1.10.4 (Harbor v2.6.4) -> harbor-helm v1.11.1 (Harbor v2.7.1)
We did an upgrade using the above path from the local clone of the SCS k8s-harbor project as follows:
kubectl --kubeconfig <path of Cluster_B kubeconfig> apply -k envs/public/
Note that the above upgrade did not set up HA mode for Harbor services, and did not set up the Swift object storage for registry service yet. It just upgraded the Harbor version and as a side effect, the upgrade process also deployed the missing ingress resource to the Cluster_B. After the successful upgrade to harbor-helm v1.11.1 (Harbor v2.7.1) we checked that everything was up and running. We then adjusted the ingress resource to allow us to access and test the upgraded Harbor instance on a different domain, other than the official https://registry.scs.community/. As we configured Harbor in Cluster_A to ReadOnly when doing the backup, the restored instance in Cluster_B was in ReadOnly as well. In order to test the whole functionality of the new instance we removed the ReadOnly mode. We tested things like creating a projects, creating a users, access to the created project, push/pull images using created user to/from the created project, etc.
After that, only two things were missing. Upgrade the Harbor services to HA mode and as a prerequisite to this redirect job service persistent storage from PV to Harbor database and also used the Swift object storage as persistent storage for registry service instead of PV.
To achieve the above we took several actions. The first thing was to create a new object storage bucket in the SCS infrastructure (in the same way how we created the bucket for Velero). Then, we upgraded Harbor again, but with the right values that enabled HA mode and adjusted the storage settings. Visit the harbor-config file for the public environment in the k8s-harbor repository to review the config. After the upgrade, Harbor services were deployed with 2 replicas, the job service used the Harbor database as storage, and the registry service was pointed to the object storage bucket. The PV of the registry service that contained all image blobs was detached. As a next action item, we spawned a helper AWS CLI pod that mounted this PV:
cat > helper-pod.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: aws-cli
spec:
volumes:
- name: registry-data
persistentVolumeClaim:
claimName: harbor-harbor-registry
containers:
- name: aws-cli
image: amazon/aws-cli
command:
- "sleep"
- "10000"
volumeMounts:
- name: registry-data
mountPath: /storage
EOF
kubectl --kubeconfig <path of Cluster_B kubeconfig> apply -f helper-pod.yaml
Using this pod we copied all image blobs from PV to the object storage.
# create `~/.aws/credentials`file with the right secrets
# sync /storage directory with the bucket
kubectl --kubeconfig <path of Cluster_B kubeconfig> exec -it aws-cli -- bash
cd /storage
aws s3 sync . s3://registry/ --endpoint-url https://api.gx-scs.sovereignit.cloud:8080
Once the sync was completed we did a test round of the whole Harbor instance again, now deployed (partially) in HA mode (Harbor database and k-v store were out of scope this time).
Finally, the new instance was in the desired state. The last steps were to configure the
DNS A record for DNS name registry.scs.community from Cluster_A IP address to
Cluster_B IP address. Right after that we also configured the ingress resource in
Cluster_B to serve the host registry.scs.community.
This final configuration caused a short outage of the SCS container registry service.
Besides this short outage, the SCS container registry service was up and accessible in
read-only mode during the whole maintenance work.