
One platform — standardized, built and operated by many.
One platform — standardized, built and operated by many.
In this post we will introduce you to our latest feature of SCS: Air-gapped installations. You will learn why this is benificial for the consumers of SCS but also for the development and testing process in general.
Table of contents:
Every installation of SCS requires an internet connection, not only for the workload on SCS, but rather for installation and updating. If you start from scratch, you need to have access to several repositories and upstream mirrors (e.g. https://pypi.org). Without them, the underlay reference implementation osism cannot provision the hardware machines with the required software components.
The main reason for having an air gapped method is of course based on customer requirements: Allowing industrial partners to host SCS as a private cloud is a major game changer when it comes to adoption of SCS in general. It allows consumers to avoid enourmous firewall configurations and therefore leads to clear visibility, traceability and the ability to audit, what is happening (or what is blocked) on your connections.
As initially mentioned, this is not the only benefit we gain by this improvement. Especially when it comes to development and testing of this huge stack of software, we often face several issues which harm us. These slow down the development process in general:
🛑 API rate limits :stop
Our testing infrastructure deploys multiple Testbeds per day, presumably using the same public IP address for these tasks. Official mirrors like dockerhub or quay for container images or pypi for python packages employ rate limits on their APIs to reduce traffic. The flipside of this measure is, that our test-deployments break. Because of the high frequency and the bulk load of downloads, our IP addresses get blocked for a certain amount of time.
🪢 Bandwidth
Debian-packages, so called deb-packages, in particular are sometimes very slow while downloading. They consume a lot of time and therefore a lot of resources over time.
⏸️ Availability
Sometimes upstream mirrors are in maintanance. Especially quay.io is very unreliable when it comes to availability. Nearly every week they have downtimes of several minutes or even hours. As we do not know when these downtimes will happen, we cannot schedule our deployments around these timeframes. Sometimes deployments get disrupted during operation which leads to all kinds of errors that involve manual debugging. Finding an unavailable upstream mirror as the reason for a failed deployment / test is tedious work and wasted worktime.
📖 SBOM generation
As we work with a humongous stack of software components, nobody is really able to trace which components are used. Generating and keeping a software bill of materials update to date is nearly impossible trough just the code repositories (which reside in multiple locations).
🔉 Auditing
Running so many services and software components leads to the problem, that you loose track which component needs to talk to the internet. Of course you can hook up a firewall in between to track and block them, but this is too much effort and requires engineering outside of the main product. The benefit in contrast to the work labor needed to keep this working is not justifiable.
🔒 Security
This point is partly also auditing. As there are too many components in the stack, we cannot keep track of the connections that are required and (hopefully not) the ones are not required. Meaning that we would not know instantly, if there is some malicious activity. We might not even notice it at all; morelikely by accident.
For the first iteration of air-gapped installations we set our goal to create mirrors for the following components: ansible collections and roles, deb packages, container images and pypi packages. Depending on the -let’s call them- asset to be mirrored, different software has be improved or even developed from the ground up.
wormhole for ansible collections and roles
Starting with more or less the most complex component: Wormhole is a completely new software that is able to mirror collections and roles from the ansible galaxy. Actually, there is other software available which should be able to mirror assets from the ansible galaxy: Pulp. Pulp would have been actually really nice, because it can also mirror other stuff like pypi packages, etc. Eventually we decided that pulp will not be the solution for us due to a variety of reasons: It is still under heavy development; it offers only OpenShift deployments or an all in one container or a bare metal installation. They will not provide (even with contribution from our side) helm charts. Additionally, the handling of pulp itself is quite aweful in general. KISS is the way we want it! Enter wormhole - the mirror software for the ansible-galaxy. It might not be pretty, but it does the job. However it did require reverse-engineering and even debugging the galaxy api. By the way: this might be the reason, why ansible itself wants to migrate to pulp. The current implementation of the galaxy is scary.
aptly for deb packages
Aptly is a project with a long history and is still being maintained. There are several implementations available, all good enough to just use them. It has a good track record as a reliable deb package mirror software. Aptly provides some sort of API functionality, but not everything we need. For the moment, we decided that this is good enough, even if it involves some manual steps. In the current version, aptly is not used in the testbed as this is under active implementation development.
registry for container images
As this is the official implementation provided from docker, we’ll just use this for container mirroring.
bandersnatch for pypi packages
Bandersnatch itself is “just” a client, but an official one. Sadly, it uses a config file which needs to contain the packages that are about to be mirrored. So no API. Therefore banderctl was developed. It mounts the config file and puts an API in front of it. The client itself is executed periodically to perform mirroring. Pretty neat! Bandersnatch and banderctl only act as supporting services outside of a testbed, as there is no need for python package installations during a testbed deployment. But for CI-CD activity, this is a big step towards more frequent and faster build times.
There is still one big problem: They all require an internet connection, but only these services require the connection. Their datastores can be pre-filled and be “manually migrated” to the air gapped installation. This however is something you still need to do on your own. We aim to prepare more information on this in the next featureset for air gapped installations.
As you might have noticed, there are some pieces to the puzzle, so let’s put it into one big image:
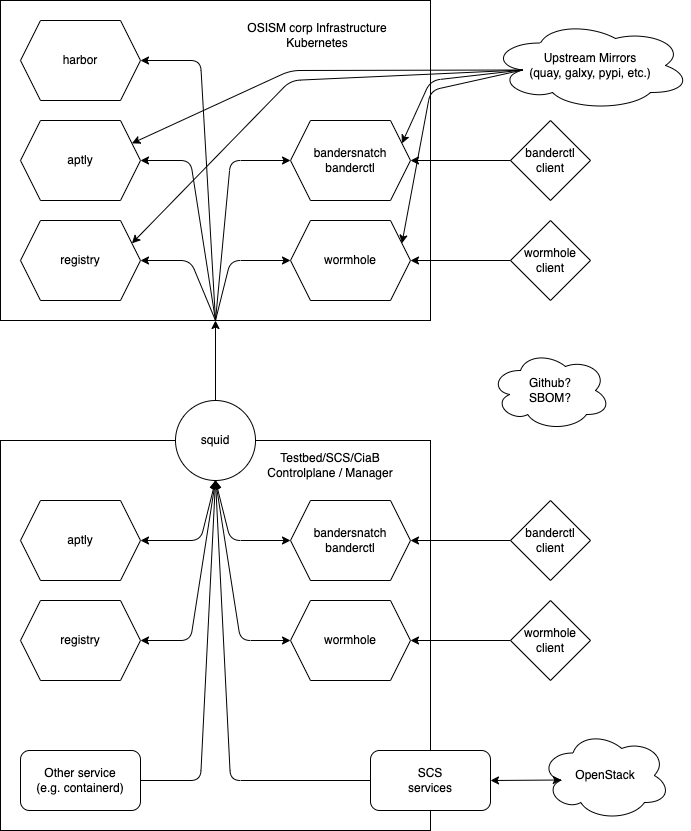
The graphic is devided into two major parts, let’s start with the upper one: This is the mirror infrastructure of OSISM GmbH. We’ll use this for our CI-CD tests and maybe also for public SCS installations in the future. The mirrors itself pull the assets from the upstream sources. You might have noticed, that there is also a component called “harbor”. Harbor deals with container images. We use it for our own build containers, therefore we’ll split container images into just “pure” mirrors and the ones we build our own.
The bottom half represents any installation of SCS, may it be a testbed, a cloud-in-a-box or similar. With a squid proxy in front requests get blocked if they want to access something else than the mirrors OSISM provides. Additionally, each deployment should also bring their own mirror stack. This will allow SCS integrators to provide these mirrors to their users resepctively.
In the middle is still something that is not clear yet: Github and SBOM. These two points still need clarification and will be refined in the future.
Wormhole can be used by you to mirror collections and roles from the official ansible galaxy. That being said, it fakes some values in the API responses (like IDs or timestamps). It would just make no sense to also store this data. Its only purpose is to mirror the assets with the versions in the correct order. Oh, by the way: There is a nasty bug inside the official galaxy client tool (and probably also the galaxy API). When querying for a latest version of a collection, the client just scrapes ALL versions and picks the highest one. Even though, the API provides a link to the latest version. Details can be found here.
Banderctl creates an API endpoint in front of the bandersnatch clients config. Bandersnatch itself is capable of a lot more things than just mirroring. But as we just require mirroring, this is still fine for us. What’s missing is an API to edit this file and append new packages or even remove packages from it. That’s where banderctl jumps right in. It translates your API request and applies the desired addition or deletion into bandersnatch’s config. Bandersnatch itself runs in parallel and is periodically executed. You do not want to trigger it on every change, as its runtime takes quite long and would throw errors, if there are parallel executions happening on the index files.
Beside the already mentioned points, we still need to implement signing for deb packages. While doing this, we might also need to consider, how we abuse the proxy to redirecting official requests (e.g. against the official quay.io from clients) to our internal mirror. Once this is done, we can continue to create a guide to preload the internal mirrors before cutting the installation from the internet. This way, we will have a fully air gapped installation finally.