
One platform — standardized, built and operated by many.
One platform — standardized, built and operated by many.
Sovereign Cloud Stack (SCS) has downgraded the formerly mandatory flavors with root disks to recommended ones in the next flavor naming standard version 3. Thus, every SCS IaaS user should preferably use the diskless flavors. This blog post describes the motivation for this change and also explains how the diskless flavors can be used with common automation (Infra-as-Code) tooling.
SCS offers the promise to make it easy for Cloud users (typically DevOps teams that develop and operate services/workloads on top of SCS IaaS and/or Container infrastructure) to move between different SCS environments and vendors or to use several of them in a federated way. One of the early accomplishments in standardizing SCS has been to standardize IaaS flavor properties and flavor naming.
On OpenStack (like on many other IaaS environments), when you create a virtual machine (VM), you can not choose an arbitrary amount of (virtual) CPUs or memory (RAM). Instead, you have a discrete set of choices, so-called flavors. They combine a number of vCPUs with a certain amount of RAM and often also a virtual disk to boot from. On a typical VM creation, an operating system image is being copied to the disk (of a size defined by the chosen flavor) on the compute host, vCPUs and RAM are allocated (according to the numbers defined in the chosen flavor) and the virtual machine can then start booting.
While this is not as flexible as some users might like, this is how most clouds
do it. In SCS environments, several standard flavors exist, e.g., flavors
with 4vCPUs, 8GiB of RAM and a 20GB root disk (SCS-4V-8-20) or one
with 4vCPUs, 16GiB of RAM and a 50GB root disk (SCS-4V-16-50).
Creating a set of flavors that caters to the needs of most users results in
a non-trivial amount of flavors. Some workloads require more computing power
(thus more vCPUs), some require more RAM. So, many combinations of these
will be needed. The mandatory flavors in SCS cover 1 through 16 vCPUs and
2 through 32GiB of RAM, with ratios of 1:2, 1:4 and 1:8 between vCPUs and
RAM (in GiB). This results in 12 flavors. (There is one additional flavor
for tiny machines, SCS-1L-1, resulting in 13 flavors actually.)
Of course, providers can implement many more based on the needs of their
users – these are just not guaranteed to be available on all SCS
environments.
Adding a variety of root disk sizes now multiplies these flavors. In versions 1 and 2 of the flavor standard, the SCS community has tried to prevent flavor explosion by just mandating one disk size per flavor, scaling it with the size of the RAM and choosing discrete values of 5, 10, 20, 50 and 100 GB for them. (By extension, providers that want to provide larger disks have been advised to choose 200, 500, 1000, … GB for these.)
Note that these root disks are not proper cinder volumes (that you could enlarge or create snapshots or backups from), but – like the so called ephemeral disks – are managed on the compute node by nova and get deleted as soon as the VM gets deleted. They are stored on the local compute node and unless the provider uses ceph storage (via rbd) for these, it makes live-migration slow (if the provider enabled block migration) or completely prevents live-migration (if the provider has not enabled block migration, for example because he uses LVM).
Next to each flavor with a root disk size (e.g. SCS-4V-16-50), SCS
also mandates a flavor without a root disk (e.g. SCS-4V-16). This is useful,
as OpenStack also allows users to boot from a preexisting disk (“volume”)
or to allocate block storage (a virtual disk) with
arbitrary size upon VM creation, although it is a bit more complicated (see
below). So we have one disk size per vCPU-RAM combination for simplicity
and the flexibility to have an arbitrary disk size with a bit more effort.
This is what we had for the SCS flavor standards v1 and v2.
With v3, we also added two flavors with (at least) local SSD type root disk storage. Adding all combinations here would have again resulted in many new flavors. Yet the cloud operators in the SCS community really wanted to avoid a proliferation of many new flavors mandated by the standards. The SCS community agreed on avoiding more mandatory flavors and instead agreed on reducing the number of mandatory flavors by stopping to require the flavors with disks (except for the two new ones with local SSDs, more on this later).
With the version 3 of the SCS flavor standard, the formerly mandatory flavors with disks have been downgraded to recommended. Operators still should provide them for the best portability of apps written against older SCS standards, but they are no longer required to in order to be able to achieve the SCS-compatible certification on the IaaS layer. We recommend that developers use the diskless flavors and allocate root disks dynamically. Using proper cinder volumes also has the additional advantage of supporting live-migration and of course to use the volume management capabilities to e.g. create snapshots or backups.
The next section explains how this can be done and uses examples from SCS’ own projects.
On the second page of the create instance dialogues, you can choose to create a new volume, chose any size you want (though you better make it large enough to accommodate the needs of the used image) and you can also choose that the disk should be destroyed upon the destruction of the VM as it would if you had used a flavor with a disk. This second page can be seen on the horizon screenshot. On the third page, choose a diskless flavor.
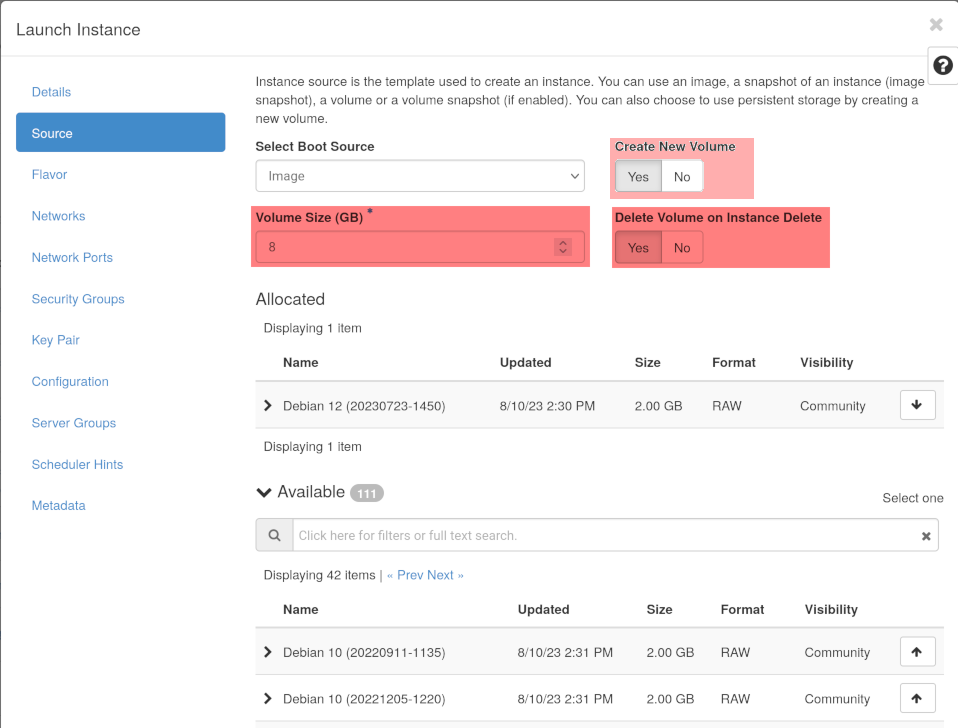
The VM instance will boot normally. You can see the volume in the volume list; it has no name, but you can see it being attached to your freshly booted VM. If you have activated the “Delete Volume on Instance Delete” setting, it will vanish as soon as you destroy the VM instance.
The fact that no name can be assigned to the volume is a limitation of the OpenStack nova API. (But of course, you could assign a name manually after it has been created.)
Horizon, of course, uses an API call to create the VM instance with
a volume allocated on the fly. This is a POST REST call to the
compute (nova) endpoint of your cloud and the settings are described
in the nova API documentation.
To allocate a disk (volume), the (optional) block_device_mapping_v2
parameter is passed with settings like
"block_device_mapping_v2": [{
"boot_index": 0,
"uuid": "$IMAGE_UUID",
"source_type": "image",
"volume_size": $WANTED_SIZE,
"destination_type": "volume",
"delete_on_termination": true,
"volume_type": "__DEFAULT__",
"disk_bus": "scsi" }]
Obviously, you would replace $IMAGE_UUID and $WANTED_SIZE with the wanted settings.
(The size is specified in GiB.)
You may leave out volume_type and disk_bus. If you leave out delete_on_termination,
it will default to false, resulting in a volume that remains allocated after the VM
instance has been removed and thus behaving differently from the root volumes that come
with a flavor with a root disk.
You can also add a tag property to place a tag on the created volume, but you
unfortunately can not add a name here.
When using the openstack SDK, the API call would be invoked with
vm = conn.compute.create_server(
name="test-diskless",
networks=[{"uuid": "2bc6b86c-77e2-4cfb-a2d1-7d7210b1e215"}],
flavor_id="82889eb7-99d0-4025-a0a3-95b3b47f792a",
key_name="SSHkey-gxscscapi",
block_device_mapping_v2=[{'boot_index': 0,
'uuid': '09337995-b91b-4763-8f6b-5e77f1d9d262',
'source_type': 'image',
'volume_size': 12,
'destination_type': 'volume',
'delete_on_termination': True}
]
)
with the fields name, uuid in networks, flavor_id, key_name,
uuid in block_device_mapping_v2, volume_size according to your
needs. Note that the block_device_mapping_v2’s uuid is the uuid
of the wanted image.
A more complete example can be found at create_vm.py.
If you are using the OpenStack command line client, you can pass the desire to create
a volume on the fly via the command line parameter --block-device.
This does not work for old versions (<5.5 / Wallaby) of the openstack CLI.
(You can work around this using the nova client rather than the openstack client
if you really need to stick to such an old version.)
Versions prior to 6.0 (Zed) also need an additional patch: These versions refuse to
issue the API call to nova because they think you have passed neither a volume
nor an image when you pass the --block-device option. This
trivial patch fixes this:
--- openstackclient/compute/v2/server.py.orig 2021-03-20 10:17:40.000000000 +0100
+++ openstackclient/compute/v2/server.py 2023-07-03 15:59:27.301268807 +0200
@@ -802,7 +802,7 @@ class CreateServer(command.ShowOne):
help=_('Create server with this flavor (name or ID)'),
)
disk_group = parser.add_mutually_exclusive_group(
- required=True,
+ required=False,
)
disk_group.add_argument(
'--image',
With a working openstack command line client, things are pretty straight-forward:
openstack server create --block-device boot_index=0,uuid=$IMGID,source_type=image,volume_size=$SIZE,destination_type=volume,delete_on_termination=true ...
will do what you need.
The openstack-health-monitor is a large shell script using the openstackclient CLI tooling to implement a scenario test against an OpenStack environment, creating routers, networks, security groups, keypairs, volumes, virtual machines, loadbalancers, etc. testing them all for correct function and then carefully cleaning up everything again. It measures the success rate as well as the timing (API performance) and stores it into an influxDB and visualizes it via grafana dashboards.
It traditionally used the SCS flavors SCS-1V-2-5 and SCS-1L-1-5 with disks by default and
would not cope with diskless flavors unless told to create and manage the root disks separately.
But this is not what was wanted, thus
PR #133
addressed this and implemented booting from diskless flavors by passing --block-device
to the nova resp. openstack client tool. Now, the flavors SCS-1V-2 and SCS-1L-1 can be used.
Hashicorp’s terraform is a flexible and popular tool to manage infrastructure and has support for many different infrastructure platforms. While it may become much less popular now after Hashicorp’s decision to stop providing it under an open source license, it is currently still in wide use, as the old free versions can still be used.
Creating a VM instance for OpenStack with terraform looks like this with a flavor with a disk:
resource "openstack_compute_instance_v2" "mgmtcluster_server" {
name = "${var.prefix}-mgmtcluster"
flavor_name = var.kind_flavor
availability_zone = var.availability_zone
key_pair = openstack_compute_keypair_v2.keypair.name
network { port = openstack_networking_port_v2.mgmtcluster_port.id }
image_name = var.image
}
In order to support a diskless flavor here (for var.kind_flavor), we’ll have to
pass a block device again. As we need the image by UUID then, we need to do a bit
of additional work to determine the UUID. Here’s the complete code …
data "openstack_images_image_ids_v2" "images" {
name = var.image
sort = "updated_at:desc"
}
resource "openstack_compute_instance_v2" "mgmtcluster_server" {
name = "${var.prefix}-mgmtcluster"
flavor_name = var.kind_flavor
availability_zone = var.availability_zone
key_pair = openstack_compute_keypair_v2.keypair.name
network { port = openstack_networking_port_v2.mgmtcluster_port.id }
# image_name = var.image
block_device {
uuid = data.openstack_images_image_ids_v2.images.ids[0]
source_type = "image"
volume_size = 30
boot_index = 0
destination_type = "volume"
delete_on_termination = true
}
}
As you can see, the image_name setting has been commented out and is replaced
by the to-be-created block device, where we again instruct OpenStack’s
compute service (nova) to create a volume from the image on the fly.
The code here is even prepared to handle cases with multiple images with the same
name and use the latest one (the one with the most recent updated_at value).
The volume_size here was chosen to be 30GB, though any value large enough to
fulfill the image’s needs can be chosen.
Of course, the root volume could also have been managed as a separate resource in terraform, allowing for a name to be used, but not allowing to have it automatically deleted on termination of the VM. Terraform does a good job at tracking resources and their dependencies, so this is not a bad option.
When creating Kubernetes (k8s) clusters on SCS, we use the K8s Cluster-API (capi) to do so. The OpenStack provider (capo) does the hard work of talking to the OpenStack API to create resources on the infrastructure, such as the virtual machines that become our control plane and worker nodes (using kubeadm to bootstrap and kubernetize them).
The OpenStack VM instances are custom resources in capo. Here is the
OpenStackMachineTemplate representation of a worker node as capo custom resource
in YAML:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha6
kind: OpenStackMachineTemplate
metadata:
name: ${PREFIX}-${CLUSTER_NAME}-md-0-${WORKER_MACHINE_GEN}
spec:
template:
spec:
cloudName: ${OPENSTACK_CLOUD}
identityRef:
name: ${CLUSTER_NAME}-cloud-config
kind: Secret
flavor: ${OPENSTACK_NODE_MACHINE_FLAVOR}
serverGroupID: ${OPENSTACK_SRVGRP_WORKER}
image: ${OPENSTACK_IMAGE_NAME}
sshKeyName: ${OPENSTACK_SSH_KEY_NAME}
securityGroups:
- name: ${PREFIX}-allow-ssh
- name: ${PREFIX}-allow-icmp
- name: ${PREFIX}-${CLUSTER_NAME}-cilium
If the flavor $OPENSTACK_NODE_MACHINE_FLAVOR is diskless, the OpenStackMachineTemplate
needs to be changed a bit:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha6
kind: OpenStackMachineTemplate
metadata:
name: ${PREFIX}-${CLUSTER_NAME}-md-0-${WORKER_MACHINE_GEN}
spec:
template:
spec:
cloudName: ${OPENSTACK_CLOUD}
identityRef:
name: ${CLUSTER_NAME}-cloud-config
kind: Secret
flavor: ${OPENSTACK_NODE_MACHINE_FLAVOR}
serverGroupID: ${OPENSTACK_SRVGRP_WORKER}
image: ${OPENSTACK_IMAGE_NAME}
rootVolume:
diskSize: ${WORKER_ROOT_DISKSIZE}
sshKeyName: ${OPENSTACK_SSH_KEY_NAME}
securityGroups:
- name: ${PREFIX}-allow-ssh
- name: ${PREFIX}-allow-icmp
- name: ${PREFIX}-${CLUSTER_NAME}-cilium
This is fairly painless: Adding the rootVolume with a rootVolume.diskSize to the
template spec and all magically works. With these instructions, the capo driver just
creates a rootVolume from the image and boots from it. Capo also keeps track of it, so
it will be removed again when the VM instance is no longer needed. So while not using
nova block_device_mapping_v2 API and it’s delete_on_termination property, the
handling is working well, as we have the capo operator taking care of the volume’s
lifecycle.
The SCS k8s-cluster-api-provider implementation is designed to work out of the box on all SCS-compatible IaaS environments. It should thus not rely on flavors that are no longer mandatory. With PR #424, the implementation was changed to create the root volume in terraform for the kind management host and to patch the cluster-template dynamically (using kustomize for robust YAML patching) for worker and control nodes if (and only if) they use a diskless flavor. There is also some heuristic to determine a reasonable volume size.
This feature is available for the SCS Release 5 (to be released in Sept. 2023) in line with
the v3 flavor spec. The control plane nodes, by default, use the new local SSD
flavor SCS-2V-4-20s to ensure robust etcd operation. The feature was also backported to
the maintained/v5.x
tree, though it needs a bit of work there still to avoid
errors
because of missing jq binary for people that upgraded by git pull.
Using the block_device_mapping_v2 in the OpenStack API or the corresponding options
in the python SDK, the openstack client CLI or terraform while using a flavor that
comes with a root disk does not create any harm. The cinder volume is still created
and used, while the disk that comes with the flavor is not accessible to the VM then.
You still want to avoid this, as you are allocating resources (local storage) that
you can’t use, but potentially have to pay for, especially on the SSD flavors. So
remember to not pass --block-device boot_index=0,... or to uncheck “Create new volume”
in horizon if you use flavors with a disk.
So when moving from flavor standard v2 to v3, we have downgraded all flavors with disks from mandatory to recommended. Yet we have added two new flavors with local SSD (or better) storage as mandatory. This looks puzzling at first.
The reason why offering local SSD storage is highly desirable is documented in the scs-0110-v1-ssd-flavors.md standard. But couldn’t we use the mechanisms described above to allocate arbitrary SSD storage when booting?
The unfortunate truth is: We can’t. This is for two reasons:
volume_type in volume
creation and then tell nova to boot from it. The downside is that
we can not set the delete_on_termination flag directly this way,
creating one more resource that needs to be tracked separately.So we need those two local SSD flavors SCS-2V-4-20s and SCS-4V-16-100s
to serve our customers well.
Instances with a flavor without a root disk are using proper cinder
volumes which can be accessed from the network. Live-migration for these
is straight-forward and we expect providers to live-migrate these
upon planned host maintance.
(Note that we have no policy yet that would mandate this, however.)
Expect VM instances on a flavor with root disk not to be live-migrated;
some providers may use rbd-backed “local” storage for these though
(which you could see from the upcoming scs:disk0-type:network extra_spec)
or enable block-migration, so you can not rely on them not being live-migrated
either. Transparency and control of live-migration will be part of future
SCS standardization work.